rCore 第6章
概述
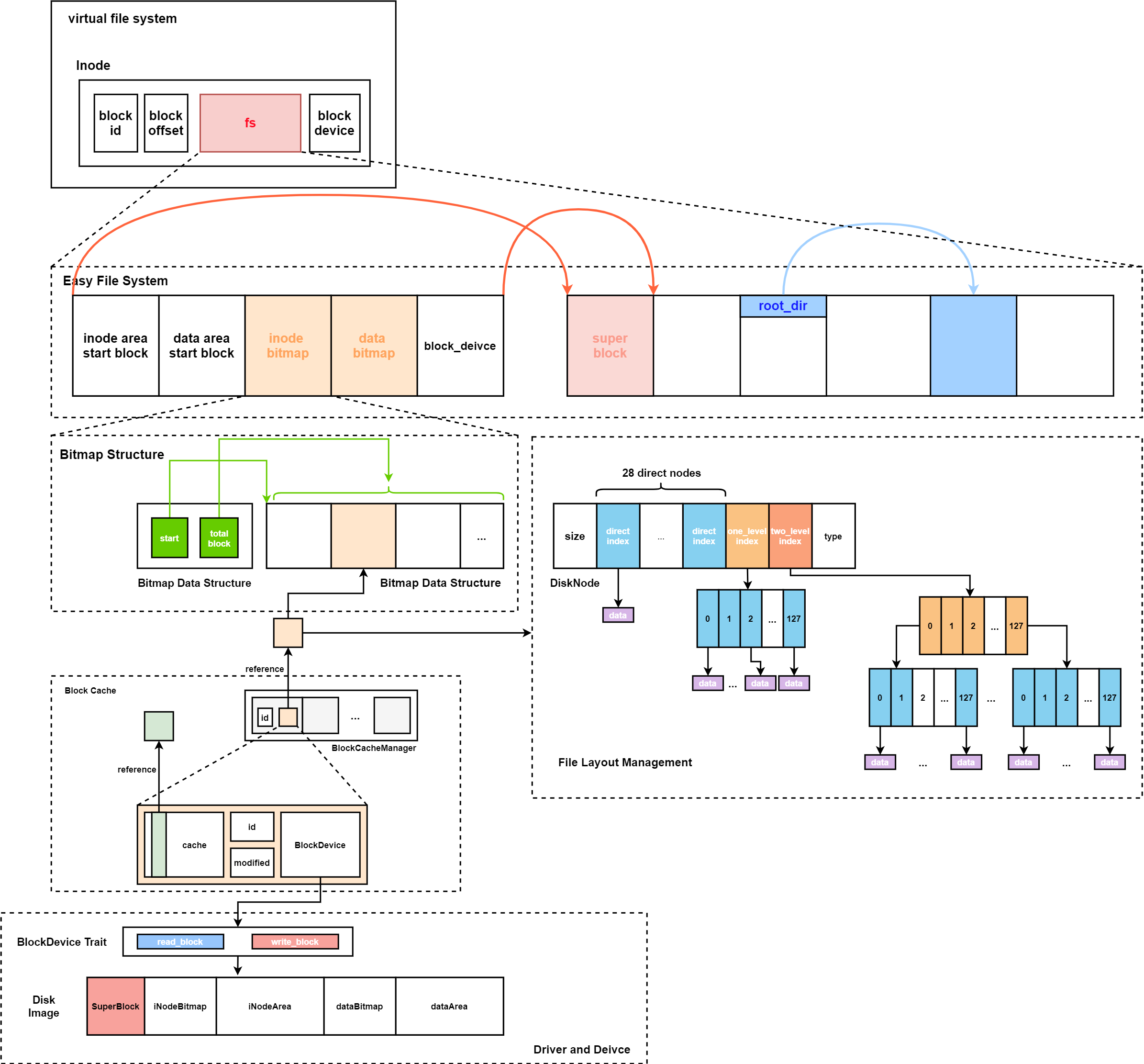
这一章节中我们要开发一个简易的文件系统,它结构层次如下图所示:
设备接口
在设备接口即图中的BlockDevice Trait处,我们只留下了接口,需要内核提供驱动。他的代码就是简单的带两个函数的Trait。
pub trait BlockDevice: Send + Sync + Any {
fn read_block(&self, block_id: usize, buf: &mut [u8]);
fn write_block(&self, block_id: usize, buf: &[u8]);
}
这里都以缓冲区为单位和块设备进行交互,我们在内存中设置一段内存作为缓冲区,缓存块设备中的数据。
块缓存
使用块缓存将所有的读写操作进行合并,如果在内存缓存区中命中,我们就不访问磁盘。同时我们使用一个数据结构将这些缓存块集中起来进行管理,
pub struct BlockCache {
cache: [u8; BLOCK_SZ],
block_id: usize,
block_device: Arc<dyn BlockDevice>,
modified: bool,
}
其中一个块有512字节,同时使用modified表示这个块是否被修改过,如果被修改过,那么这个块在调出缓存时,将会将这个块写回块设备。
我们为缓存块实现了read和modify方法,供上层调用。
pub fn read<T, V>(&self, offset: usize, f: impl FnOnce(&T) -> V) -> V {
f(self.get_ref(offset));
}
pub fn modify<T, V>(&mut self, offset: usize, f: impl FnOnce(&mut T) -> V) -> V{
f(self.get_mut(offset));
}
这里传入了一个闭包类型FnOnce,它将对当前缓存块进行操作。
我们设置了16个块缓存交给BlockCacheManager进行管理,我们获取一个块缓存需要调用BlockCacheManager的方法。
impl BlockCacheManager {
pub fn get_block_cache(
&mut self,
block_id: usize,
block_device: Arc<dyn BlockDevice>,
) -> Arc<Mutex<BlockCache>> {
if let Some(pair) = self.queue
.iter()
.find(|pair| pair.0 == block_id){
Arc::clone(&pair.1)
} else {
if self.queue.len() == BLOCK_CACHE_SIZE {
if let Some((idx, _)) = self
.queue
.iter()
.enumerate()
.find(|(_, pair)| Arc::strong_count(&pair.1) == 1){
self.queue.drain(idx..=idx);
} else {
panic!("Run out of BlockCache!");
}
}
let block_cache = Arc::new(Mutex::new(BlockCache::new(
block_id,
Arc::clone(&block_device),
)));
self.queue.push_back((block_id, Arc::clone(&block_cache)));
block_cache
}
}
}
代码中会遍历所有的缓存块,匹配块号相同的块缓存进行返回。如果不存块号相同的缓存块则会对队列进行遍历,找到引用计数为1的块,对这个块进行回收,同时读入新的块并加入队列。
BitMap结构
这里所有的inode和数据块都通过BitMap进行管理,这里使用了两个类型对位图进行描述:
type BitmapBlock = [u64; 64];
pub struct BitMap {
start_block_id: usize,
blocks: usize,
}
这里我们子需要记录位图的起始块和总的大小,具体的块使用BitmapBlock进行描述。我们使用get_block_cache方法获取到块缓存后可以,设置了方法alloc和dealloc进行对位图中bit进行置位和消除。
Layout
这个文件实现了一个文件的块设备布局结构,我们设置了多级索引,直接索引存在28个,一级索引存在1个,2级索引1个,每个索引是4字节,所以一个block中最多128个索引。
Layout的读写都需要对直接索引、一级索引和二级索引进行讨论,
Easy File System
Easy File System对于整个文件系统的磁盘布局进行了描述,它的结构如下:
pub struct EasyFileSystem {
pub block_device: Arc<dyn BlockDevice>,
pub inode_bitmap: Bitmap,
pub data_bitmap: Bitmap,
inode_area_start_block: u32,
data_area_start_block: u32,
}
这里的代码实现了每个分区在磁盘的位置,块的回收和分配都将通过Easy File System进行分配和调度。创建一个这样的文件系统需要分为以下的几步。
- 计算各个分区需要包含多少的块,先需要计算
inode位图的大小,获取inode区域的大小。剩余的区域要留给数据区和数据位图。 - 创建
Easy File System的数据结构 - 对我们使用的块进行全部的清零。
- 对超级块根据文件系统的数据进行初始化。
- 创建0号
iNode进行初始化的根目录。
Virtual File System
在这一层提供暴露给用户的结构,对用户隐藏磁盘的操作。用户可以看见iNode的结构。
pub struct Inode {
block_id: usize,
block_offset: usize,
fs: Arc<Mutex<EasyFileSystem>>,
block_device: Arc<dyn BlockDevice>,
}
这里实现的方法大多都采用了传入一个函数的方法进行回调。
impl Inode {
fn read_disk_inode<V>(&self, f: impl FnOnce(&DiskInode) -> V) -> V {
get_block_cache (
self.block_id,
Arc::clone(&self.block_device)
).lock().read(self.block_offset, f)
}
}
这个方法期待调用传入一个函数,这个函数的接受的参数为一个DiskInode的引用,起始就是get_block_cache().lock().read()之后自动换传给f进行回调的参数。
如我们用它实现一个find方法。
impl Inode {
pub fn find(&self, name:&str) -> Option<Arc<Inode>> {
let fs = self.fs.lock();
self.read_disk_inode(|disk_inode|{
self.find_inode_id(name, disk_inode)
.map(|inode_id|{
let (block_id, block_offset) = fs.get_disk_inode_pos(inode_id);
Arc::new(Self::new(
block_id,
block_offset,
self.fs.clone(),
self.block_device.clone(),
))
})
})
}
fn find_inode_id(
&self,
name: &str,
disk_inode: &DiskInode,
) -> Option<u32> {
assert!(disk_inode.is_dir());
let file_count = (disk_inode.size as usize) / DIRENT_SZ;
let mut dirent = DirEntry::empty();
for i in 0..file_count {
assert_eq!(
disk_inode.read_at(
DIRENT_SZ * i,
dirent.as_bytes_mut(),
&self.block_device,
),
DIRENT_SZ,
);
if dirent.name() == name {
return Some(dirent.inode_numer() as u32);
}
}
}
}
这里我们先从find_inode_id开始解析,对这个inode从磁盘进行读取后,可以调用这个函数进行分析,对于文件的数据进行遍历,找到名字相同的想返回这个目录的inode_id。
之后介绍find, 这里先获取了Easy File System的锁,所有对于文件系统的使用,全程都要持有互斥锁。获取完锁之后,会通过read_disk_inode方法调用匿名函数,通过名字获得id后生成一个inode进行返回。
测试
在用户态测试easy-fs的功能,我们需要在用户态为efs实现BlockDevice Trait,这样就可以使用Inode操作文件系统了。我们使用Linux的文件系统来模拟底层的块设备。
use std::fs::File;
use easy-fs::BlockDevice;
const BLOCK_SZ: usize = 512;
struct BlockFile(Mutex<File>);
impl BlockDevice for BlockFile {
fn read_block(&self, block_id: usize, buf: &mut[u8]) {
let mut file = self.0.lock().unwrap();
file.seek(SeekFrom::Start((block_id * BLOCK_SZ) as u64))
.expect("Error when seeking!");
assert_eq!(file.read(buf).unwrap(), BLOCK_SZ, "Not a complete block!");
}
fn write_block(&self, block_id: usize, buf:&[u8]) {
let mut file = self.0.lock().unwrap();
file.seek(SeekFrom::Start((block_id * BLOCK_SZ) as u64))
.expect("Error when seeking");
assert_eq!(file.write(buf).unwrap, BLOCK_SZ, "Not a complete block!");
}
}
这样我们实际操作就是Linux的File, 我们通过在文件中seek并进行读写就可以模拟对块设备进行读写。
之后我们需要创建文件镜像,实际上就是创建一个文件,内容是我们Easy File System的镜像内容。
use clap::{Arg, App}
fn easy_fs_pack() -> std::io::Result<()> {
let matches = App::new("EasyFileSystem packer")
.arg(Arg::with_name("source")
.short("s")
.long("source")
.takes_value(true)
.help("Executable source dir(with backslash)")
)
.arg(Arg::with_name("target")
.short("t")
.long("target")
.takes_value(true)
.help("Executable target dir(with backslash)")
)
.get_matches();
let src_path = matches.value_of("source").unwrap();
let target_path = matches.value_of("target").unwrap();
println!("src_path = {}\ntarget_path = {}", src_path, target_path);
let block_file = Arc::new(BlockFile(Mutex::new({
let f = OpenOptions::new()
.read(true)
.write(true)
.create(true)
.open(format!("{}{}", target_path, "fs.img"))?;
f.set_len(8192 * 512).unwrap();
f
})));
let efs = EasyFileSystem::create(
block_file.clone(),
8192,
1
);
let root_inode = Arc::new(EasyFileSystem::root_inode(&efs));
let apps: Vec<_> = read_dir(src_path)
.unwrap()
.into_iter()
.map(|dir_entry|{
let mut name_with_ext = dir_entry.unwrap().file_name().into_string().unwrap();
name_with_ext.drain(name_with_ext.find('.').unwrap()..name_with_ext.len());
name_with_ext
})
.collect();
for app in apps {
let mut host_file = File::open(format!("{}{}", target_path, app)).unwrap();
let mut all_data: Vec<u8> = Vec::new();
host_file.read_to_end(&mut all_data).unwrap();
let inode = root_inode.create(app.as_str()).unwrap();
inode.write_at(0, all_data.as_slice());3
}
}
这里首先使用clap 对输入进行了分析,-s表示输入的源文件,-t表示目标文件。获取完这些参数后,通过Linux的文件系统创建一个可读可写的大小为4MB的fs.img文件。 之后将这个文件作为块设备,创建Easy File System,并读取这个文件系统根目录。紧接着读取我们的源文件目录下的源文件名进行读取,生成目录下的文件名列表,之后通过在文件系统中创建inode,设置文件名,并将app的二进制内容写入对应的inode中。
接入内核
UserBuffer
有了文件的抽象后,操作系统就可以将需要读写并持续存储的文件按文件来管理,并把文件分配给进程,让进程以很简洁的同一抽象接口File来读写文件。
pub trait File: Send + Sync {
fn read(&self, buf: UserBuffer) -> usize;
fn write(&self, buf: UserBuffer) -> usize;
}
这个接口建立起了内存和存储设备之间的联系,其中UserBuffer是我们mm模块中定义的在应用地址空间中的一段缓冲区。我们为OSInode实现了File Trait, 这样OSInode就可以调用read或者write和UserBuffer进行交互。
impl File for OSInode {
//...
fn read(&self, mut buf: UserBuffer) -> usize {
let mut inner = self.inner.exclusive_access();
let mut total_read_size = 0usize;
for slice in buf.buffers.iter_mut() {
let read_size = inner.inode.read_at(inner.offset, *slice);
if read_size == 0 {
break;
}
inner.offset += read_size;
total_read_size += read_size;
}
total_read_size
}
fn write(&self, buf: UserBuffer) -> usize {
let mut inner = self.inner.exclusive_access();
let mut total_write_size = 0usize;
for slice in buf.buffers.iter() {
let write_size = inner.inode.write_at(inner.offset, *slice);
assert_eq!(write_size, slice.len());
inner.offset += write_size;
total_write_size += write_size;
}
total_write_size += write_size;
}
}
读写时,由于UserBuffer中的buffers是一个Vec<&'static mut[u8]>, 所以buf.buffers.iter()就是遍历vec,对每一个u8数组进行读写。read和write完成对于inode进行buffers的读和写,返回值是读写的字节数。
块设备
在qemu中我们使用了virtio设备。
#[cfg(feature = "board_qemu")]
type BlockDeviceImpl = virtio_blk::VirtIOBlock;
#[cfg(feature = "board_k210")]
type BlockDeviceImpl = sdcard::SDCardWrapper;
lazy_static! {
pub static ref BLOCK_DEVICE: Arc<dyn BlockDevice> = Arc::new(BlockDeviceImpl::new());
}
这里virtio_blk::VirtIOBlock实现了BlockDevice Trait,所以我们根据编译选项,确定使用哪一个实现。
同时在qemu启动时,我们要将我们的磁盘镜像挂载到qemu的mmio接口上。
-drive file=fs.img,if=none,format=raw,id=x0 \
-device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
将我们的fs.img命名为x0,之后,将x0作为virtio总线上的一个块设备接入,之后再设定通过mmio进行控制。
在qemu的代码中,我们可以代码,qemu的riscv版本,virtio的mmio地址空间为从0x10001000开始的4KB,于是我们必须进行如下的映射。
#[cfg(feature = "board_qemu")]
pub const MMIO: &[(usize, usize)] = &[
(0x10001000, 0x1000),
];
在内核初始化时,这段内存已经被映射。
impl MemorySet {
pub fn new_kernel() -> Self {
//...
println!("mapping memory-mapped registers");
for pair in MMIO {
memory_set.push(MapArea::new(
(*pair).0.into(),
((*pair).0 + (*pair).1).into(),
MapType::Identical,
MapPermission::R | MapPermission::W,
), None);
}
memory_set
}
}
对这对区间进行恒等映射,并开放了读写权限。
pub struct VirtIOBlock(Mutex<VirtIOBlk<'static'>>);
impl VirtIOBlock {
pub fn new() -> Self {
Self(Mutex::new(VirtIOBlk::new(
unsafe { &mut *(VIRTIO0 as *mut VirtIOHeader) }
).unwrap()))
}
}
impl BlockDevice for VirtIOBlock {
fn read_block(&self, block_id: usize, buf: &mut [u8]) {
self.0.lock().read_block(block_id, buf).expect("Error when reading VirtIOBlk");
}
fn write_block(&self, block_id: usize, buf: &[u8]) {
self.0.lock().write_block(block_id, buf).expect("Error when writing VirtIOBlk");
}
}
我们在VirtIOBlk进行进一步的封装,加上一层互斥锁变为我们的VirtIOBlk,传入的VirtIOHeader起始就是以mmio进行访问的VirtIO需要的一组寄存器。之后为VirtIOBlk实现BlockDevice的Trait即可。VirtIO设备需要占用部分内存,放置一个数据结构VirtQueue,CPU可以向VirtIO发送请求,也可以从队列中获取结构。
qemu为我们暴露的接口如下:
extern "C" {
fn virtio_dma_alloc(pages: usize) -> PhysAddr;
fn virtio_dma_dealloc(paddr: usize, pages: usize) -> i32;
fn virtio_phys_to_virt(paddr: PhysAddr) -> VirtAddr;
fn virtio_virt_to_phys(vaddr: VirtAddr) -> PhysAddr;
}
我们使用rCore中的相关方法进行实现。
lazy_static! {
static ref QUEUE_FRAMES: Mutex<Vec<FrameTracker>> = Mutex::new(Vec::new());
}
#[no_mangle]
pub extern "C" fn virtio_dma_alloc(pages: usize) -> PhysAddr {
let mut ppn_base = PhysPageNum(0);
for i in 0..pages {
let frame = frame_alloc().unwrap();
if i == 0 { ppn_base = frame.ppn; }
assert_eq!(frame.ppn.0, ppn_base.0 + i);
QUEUE_FRAMES.lock().push(frame);
}
ppn_base.into()
}
这里连续地申请了pages个页帧,之后将这些页帧加入到了队列中,之后返回申请到的物理地址。之后几个方法也用rCore中的方法实现。
内核中的Inode
内核中需要控制Inode的访问方式,这里进行进一步的封装。
pub struct OSInode {
readable: bool,
writable: bool,
inner: Mutex<OSInodeInner>,
}
pub struct OSInodeInner {
offset: usize,
inode: Arc<Inode>,
}
impl OSInode {
pub fn new(
readable: bool,
writable: bool,
inode: Arc<Inode>,
) -> Self {
readable,
writable,
inner: Mutex::new(OSInodeInner {
offset:0,
inode,
})
}
}
offset和我们在C中的文件语义类似,不过这个offset这里不是一个每次打开就有一个。
文件描述符表
文件打开和关闭都是以进程为单位在进行,我们这里需要在进程控制块中加入文件描述符表
pub struct TaskControlBlock {
//...
pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,
}
这里的dyn表示实现了File + Send + Sync三个Trait的类型,我们调用其read等方法时,可以在运行时动态确定调用的函数。我们要添加入的文件类型,OSInode、Stdout、Stdin都实现了这三个方法。
为内核实现文件访问机制
应用程序访问文件前需要对文件系统进行初始化,可以通过应用程序发出系统调用如mount实现,也可以操作系统直接实现。我们这里只需要在初始化时进行实现即可。
lazy_static! {
pub static ref ROOT_INODE: Arc<Inode> = {
let efs = EasyFileSystem::open(BLOCK_DEVICE.clone());
Arc::new(EasyFileSystem::root_inode(&efs))
};
}
之后我们实现四个系统调用。
pub fn open_file(name: &str, flags: OpenFlags) -> Option<Arc<OSInode>> {
let (readable, writable) = flags.read_write();
if flags.contains(OpenFlags::CREATE) {
if let Some(inode) = ROOT_INODE.find(name) {
// clear size
inode.clear();
Some(Arc::new(OSInode::new(
readable,
writable,
inode,
)))
} else {
// create file
ROOT_INODE.create(name)
.map(|inode| {
Arc::new(OSInode::new(
readable,
writable,
inode,
))
})
}
} else {
ROOT_INODE.find(name)
.map(|inode| {
if flags.contains(OpenFlags::TRUNC) {
inode.clear();
}
Arc::new(OSInode::new(
readable,
writable,
inode
))
})
}
}
这里通过创建时的参数,判断是否要创建一个文件,是否要清空原本的文件。有了这个函数我们就可以很方便的实现sys_open。
pub fn sys_open(path: *const u8, flags: u32) -> isize {
let task = current_task().unwrap();
let token = current_user_token();
let path = translated_str(token, path);
if let Some(inode) = open_file(
path.as_str(),
OpenFlags::from_bits(flags).unwrap()
) {
let mut inner = task.acquire_inner_lock();
let fd = inner.alloc_fd();
inner.fd_table[fd] = Some(inode);
fd as isize
} else {
-1
}
}