CLEPSYDRACACHE – Preventing Cache Attacks with Time-Based Evictions
背景
近年来,对于CPU微架构的攻击层出不穷。特切实针对Cache的攻击扮演了很重要的角色,这些攻击都利用了Cache地址冲突。这篇文章中提出了Clepsydra Cache ,通过Cache Decay和随机化方法来消除Cache Side Channel。文章提出了一种动态调度机制Time To Life,来保持消除Side Channel的同时保证性能。
Cache是主存和CPU之间的结构,用于缓解由于访问内存的高延迟。现代处理器往往每个核心都有自己的单独的L1和L2 Cache,但是LLC是在所有核之间共享的。因为Cache不能容纳所有的数据,所以必须要合适替换Cache块来给新的数据。
从架构的角度来讲,Cache对于软件来说是透明的。但是由于Cache是基于局部性原理的,基于Cache Timing Attack可以看见Cache。通过测量一次内存访问的时间,可以判断访问的数据是否被Cache了。因为共享Cache的存在,所以攻击者可以很好地利用起发起进程级,甚至虚拟机级的攻击。
因为Cache是为了加速主存访问出现的,所以Timing Side Channel的消除往往不能避免性能的损失。Detection-based的机制不能很好地解决问题,因为不同软件的访问模式有很大的不同。因此最近的设计都改变了新数据被Cache的方式。如Cache partitioning将Cache分为不同的安全域从而达到隔离的效果。另一方面,index随加化则是通过随机化地址到Cache entry的映射,可以加大找到驱逐集的难度,从而加大PRIME+PROBE的难度。但是最近的研究显示,只是Index随机化不能充分地保证安全,需要不断地进行重新映射。攻击者仍旧可以构建一个驱逐集来驱逐一个目标地址。但是不幸的是,频繁地进行重新映射是不切实际地,因为它会导致非常大的性能开销,甚至整个Cache的Flush。
这篇文章提出了Clepsydra Cache,提出了一种安全的Index-Based随机化方案,可以防御最先进的Cache Based Attack并且保证Cache的性能。通过Cache Decay加上Index-Based随机化可以防御PRIME + PRUNE + PROBE的攻击。Index-Based随机化指的是随机化地址到Cache Entry的映射,而Cache Decay是通过硬件集成的Time-to-Live来进行Cache Evict来使得对于Cache Conflict的观察变得困难。
基础知识及相关工作
Cache是否命中导致内存访问延迟可以利用于侧信道攻击,一个攻击者可以观察其他进程的Cache访问时间,来推断它访问的数据。在PRIME+PROBE攻击中,一个在Cache的区域中填充上自己的数据,接下来被攻击的进程会在访问内存的过程中,驱逐一些Cache块。最后一步,攻击者通过重新测量自己填入数据的访问时间来得知被攻击进程的访问地址。一开始PRIME+PROBE的攻击都用于和CPU比较近的Cache,因为Evict LLC大部分表项的代价非常大。但是最近PRIME+PROBE攻击使用最小驱逐集可以实现对于LLC的攻击(驱逐集指的就是映射到同一个Cache Set的地址的集合)。而最小驱逐集合指的是集合中地址的数量等于Cache way的数量的驱逐集。如果攻击者可以创建这样一个集合,那么就可以快速清空被攻击程序在Cache中的数据包括LLC。但是通过 地址很难控制物理地址的映射,为了克服这些,已经有论文设计高效获取最小驱逐集的算法。同时FLUSH+RELOAD攻击不需要获取驱逐集,并且不需要和被攻击者共享内存。
最近的PRIME+PRUNE+PROBE还可以用于攻击使用使用Index随机化的架构。通过构建一个普遍的驱逐集,可以在一个合理的时间内驱逐一个Cache Entry。但是文章中说明这种攻击对于本篇工作是无效的。
威胁模型
- 我们假设攻击在一个理想的,无噪声的环境中,因此攻击者可以完美地区分Cache命中和Cache缺失。
- 攻击者可以访问任何数量的地址。
- 可以测量执行程序的执行时间。
- 假设随机化使用的函数是伪随机。
- 不考虑一系列的物理攻击。
Clepsydra Cache
在传统的Cache中,Cache Entry要么可以被一条指令进行替换,要么因为Cache conflict被替换。现在的攻击都基于上面两点中的任何一点。前一点,可以通过不提供这样的指令解决(实际上很多ISA不提供单独刷新某一个Cache Entry的指令);后面一点,则是现在Cache设计中的基本问题,由它引起的漏洞很难消除。
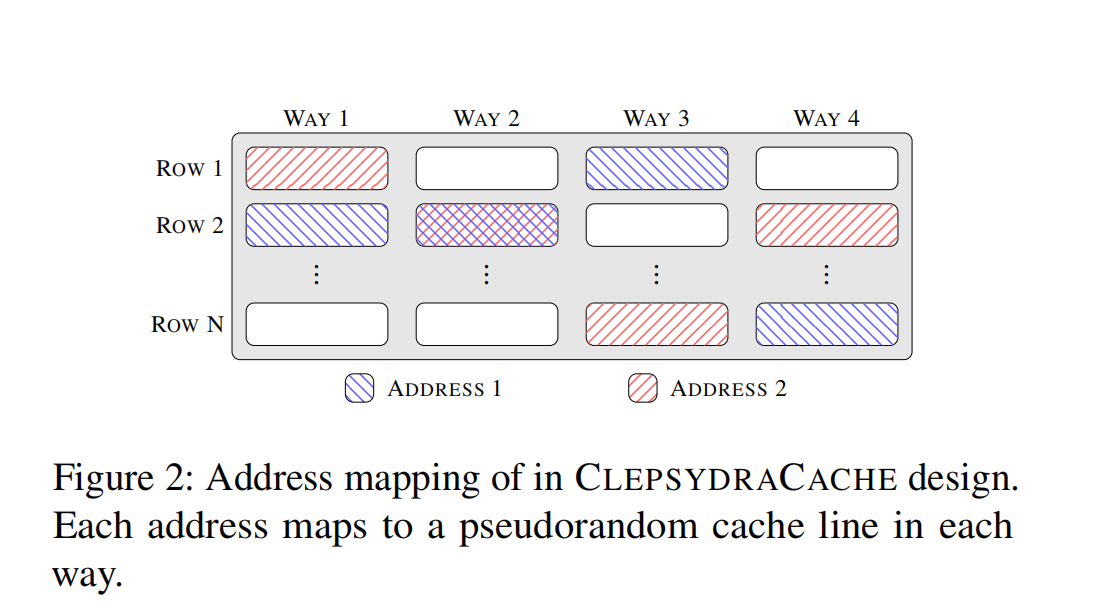
Clepsydra Cache的设计目标就是大幅度减少总的Cache Conflict,这样Cache访问和Cache替换之间的直接关系就可以大大减弱。在文章的设计中,达到了这一目标,于是可以很好地防御PRIME+PROBE和PRIME+PRUNE+PROBE的攻击。在Clepsydra Cache,除了因为Cache Conflict进行替换,每一个Cache Entry添加了一个TTL(Time to life)项。这个TTL被随机初始化,然后以的速率减少,如果TTL变为0就意味着这个Entry需要被驱逐。第二点,Clepsydra Cache使用一个高度随机的地址映射机制,这样不通过观察Conflict就得知驱逐集就变得不可能了。
为了实现高性能的Cache,Clepsydra Cache不通过主动检查TTL是否为0,将Cache Entry置为无效,而是通过在Cache访问时检查TTL位而不是Valid实现。同时高性能的Cache也要求这个随机映射函数的延迟必须很低。
TTL
在每个Entry中,都有一个TTL表项意味着这个Entry还可以在Cache中滞留多久。一旦一个Cache Miss发生,需要将一个Cache块载入到Cache中,随机映射函数会决定映射的Entry,同时一个随机的TTL会被写入Entry。TTL会随时间不断减少,一个Cache Access如果TTL > 0, 意味访问成功,之后设置一个新的TTL;反之失败。
地址映射和替换
传统的Cache中地址中的Index部分决定了数据被缓存到的Cache Line。因此在已知映射策略的情况下,获取最小驱逐集就变成一件平常的事。文章中将地址映射到一个Dynamic Set,即使冲突是不可避免的,文章仍然设计了一个伪随机函数,这个伪随机函数是和真正的随机函数不可区分的。
这里函数会将一个t Bits的Tag和一个i Bits的Index映射到 Bits的Tag和i Bits的Cache Index。函数的性质如下:
- 可逆性:即两个不同的地址不能最后函数的输出相同。
- Index伪随机:不同的地址映射同一个Cache Line的概率必须接近
- 独立性:函数在不同Cache Way的映射情况必须是独立的。
这里使用的是一个轻量级的Block Chiper,具体来说是PRINCE,可以在两个Round做到全混淆。
冲突解决
Clepsydra Cache中可以动态地控制Entry 表项全局的速率,用表示TTL下降的速率。每个周期 会自动减1直到一个最小值,一旦一个Cache Conflict发生时, 的翻倍。通过这样的策略在减少Cache Conflict和维持性能之间达到平衡。

安全性分析
对TTL进行统计观察
文章中对于攻击者是否能区分Cache Conflict和Time-based Cache eviction进行了分析。在传统的Cache攻击中,一次冲突检测分为两个阶段。第一个阶段,攻击者会准备一些Candidate Addresses,之后访问目标地址,就会将一个Candidate Address驱逐出Cache。下一个阶段,通过测量访问Candidate Address得知那些Address被替换出Cache。但是在Clepsydra Cache中,就会引入一定程度的不确定性,攻击者无法确定一次访问的表项驱逐到底是Time-based还是Conflict-based。但是,在Candidate Address的集合很小的情况下,在驱逐和观察的时间间隔会很短,于是Time-based的驱逐可能性就变得很低。文章中指出,一次有效的攻击不可能执行用很小的Candidate Address集合,这个将在下一节中进行说明。
一个强大的攻击者还可能估计的值,从而获取Cache Conflict的信息。为了做到这一点,攻击者需要有一个地址集并且间歇地访问它们,判断是否有Cache Miss发生。
Prime+Prune+Probe 攻击
Prime+Prune+Probe攻击需要构建一个驱逐集, 表示和目标地址在Cache中冲突且在的一个地址。在Clepsydra Cache构建这样的集合是困难的,主要是如下三个原因:
- 初始的Prime过程,需要占据所有的地址的Cache表项。
- Time-based的驱逐策略,要求两次访问的间隔的时间不能太长。
- 最终的驱逐集要占据一个Dynamic Set的所有表项。
Catching的概率
在开始,攻击者需要不断地访问一个地址集合, 最终是的一个子集,表示去除了一些Cache表项重复的地址,获取较小的一个地址集合。之后文章中使用去表示在使用个地址作为填充表项时,地址x一定可以驱逐中的一个表项的概率。由上面的分析可以知道,如果一个Dynamic Set如果没有被完全填满,那么Catching的概率就是0,因为这样不会导致任何的Cache Conflict。而又Clepsydra的设计原则可以知道,它总是尽量保证每一个Dynamic Set都有空闲的Entry。随意为了进行Catching,我们对它的概率进行计算。假设在一个没有噪声的环境中,地址x映射到某一个Dynamic Set,可以完全包含这个Dynamic Set的概率满足超几何分布,这里作者对于公式进行了化简:
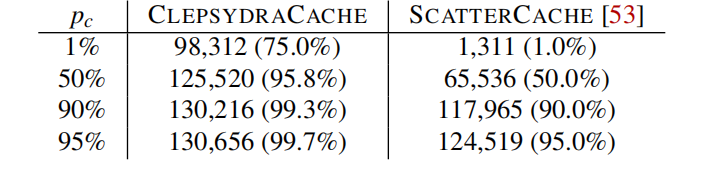
文章中将几个典型的数据代入,为了达到50%的概率,要填充Cache 95.8%的表项,这相较于另外一片工作的Scatter Cache无疑是安全性的巨大提升。
Time-Based驱逐
地址集合是从原始集合k缩小得来的,经过上一节的讨论可以知道,我们的目标是几乎填充满Cache Entry。同时攻击者需要尽量缩小Time-Based驱逐带来的影响,这样才能检测到Conflict。这需要将保持在一个较小的值,才能保证攻击对于Conflict的观测。但是根据传统的攻击,在探测的步骤中,需要对整个地址集合进行遍历,这样将会指数级上升。因此更好的办法是,渐进地使用Prime + Probe,在迭代的过程中,需要不断地访问已有的来刷新,使得保持在一个较低的值。
现在假设攻击将Cache prime到了一个足够的程度,于是访问x可以极大概率发生Conflict。但是攻击者现在需要逐个进行Probe来检测,到底是哪一个地址被x驱逐出了Cache。文章中指出了,到了Probe到一个Cache Miss发生时,已经无法保证这到底时Time-Based驱逐还是Conflict-Based驱逐,即攻击者还是没能攻破TTL机制,这可能需要设计好TTL的值,一个太大的TTL无法做大这个保证,作者还给出要完成Prime到这个程度所需要的访问次数公式,可以作为设计TTL的参考。于是攻击只能将所有潜在的地址加入驱逐集G中,毫无疑问,这大大增加了G的大小。

驱逐的概率
为了实施一次Cache Timing Attack需要找到和x冲突许多Cache Entry。文章中接下来计算了到底现需要多少地址来以的概率检测到地址x的访问。
在G中每一个地址都的概率覆盖地址x的Dynamic Set中的一个地址,于是有如下的公式:
其中 的意思是G中有地址命中x的Dynamic Set中的的概率,所以整个Dynamic Set被占满,由独立性可以得到,可以直接取w的幂次。文章同样在这里带入了典型数据进行说明
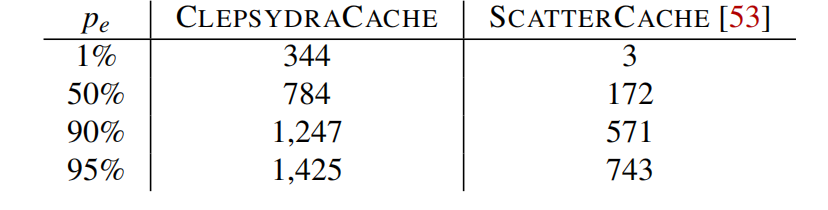
在一个16路的Cache中如果要以95%的概率占满一个Dynamic Set,这个G的大小要达到1425。
Profile性能估计
文章中还保守估计了攻击者在Clepsydra Cache构造一个驱逐集G所要花费的时间。这里做了假设一次Cache Hit的时间为10 ns,Cache Miss的延迟为20ns。
攻击者使用上文描述的方法进行攻击,每一次新地址的访问一定会操作一次Cache Miss,由于是递进式地扩大k,同时每次访问时添加地新地址都有和k中已有的地址发生碰撞。为了防止的快速增加同时保持k原本包含的地址,需要再次访问原本k集合中的地址,这个过程又有的概率触发碰撞。
首先第一个全加符号表示这个集合k的大小是从1到|k|的。每一次集合扩大新的地址一定带来一次Miss,同时在重现访问k中地址的过程中触发配装,如果触发碰撞要继续访问直到地址都在Cache中稳定。
每一次只能构建G中的一个地址,根据G所需要的大小,可以计算总的时间。使用这个估计,如果要以50%的概率占满一个攻击地址的Dynamic Set,同时假设Cache的大小为8 MB且是16路的。在k只是用Cache的70%是,需要使用1个小时,k只是用50%的Cache表项,这个时间将扩大到19个小时。
实现
Clepsydra Cache在gem5上实现了对于微架构的模拟,同时分析了实际硬件的实现开销。对于随机函数的实现采用了轻量级的Block Cipher PRINCE,使用三轮的混淆和一个64位的密钥。至于TTL的实现,文章中为每一个表项实现了一个计数器,同时设定为50ms。而硬件实现上,作者模拟了65nm工艺下的情况,面积开销为0.1平方毫米,同时功耗增加了12毫瓦。
测试
Parsec benchmark使用了全模拟的模式,之后的benchmark由于时间开销太大不会使用全模拟。可以看到在Parsec benchmark中使用Clepsydra Cache会有 -0.37% 到 5.25%的开销。
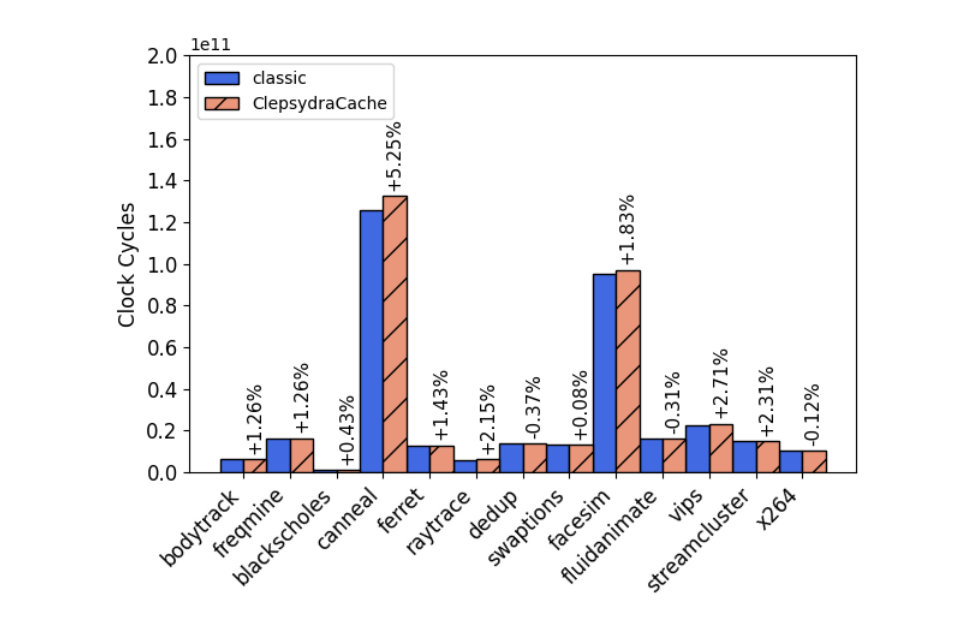
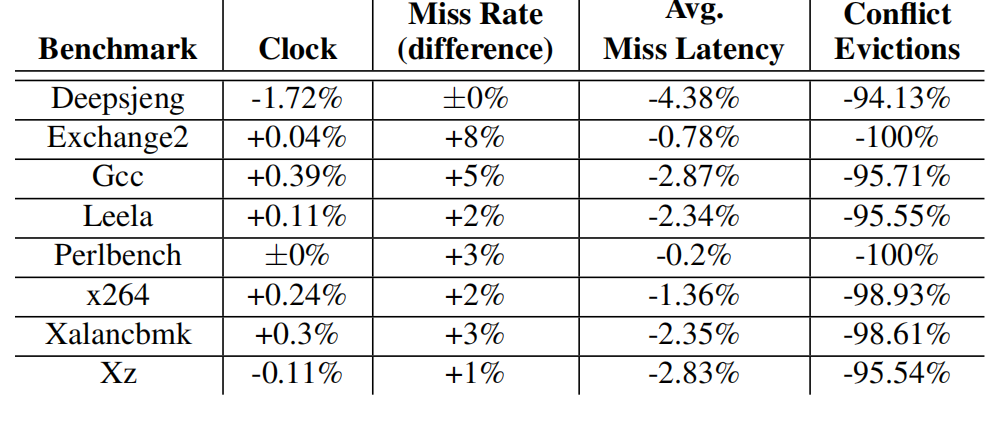
而在SPEC CPU 2017的测试,文中绘制了一个表格如下:
总结
文中利用TTL机制达到了估计者对于Conflict和TTL Evict的不可区分,防御了Prime + Prune + Probe攻击。同时证明了硬件实现上的可行性,还有运行可以小开销甚至无开销。